
Extract Text from Web Pages A Practical Guide
Learn how to extract text from web pages with actionable methods. This guide covers everything from simple copy-paste to advanced Python and no-code tools.
You've got a few solid ways to pull text from a web page. The simplest is a good old copy-paste, but you can also use your browser's developer tools, run some Python libraries for automation, or use no-code scraping tools. Each approach strikes a different balance between speed, technical know-how, and the precision you need, whether you're just grabbing a paragraph or mining thousands of pages.
Why Bother Extracting Text from a Web Page?
In an age where we're swimming in digital information, knowing how to grab text from a website has become a surprisingly critical skill. This isn't just some niche task for developers anymore. It’s a core competency for anyone who needs to make smart, fast decisions. Think of it as the difference between passively reading the web and actively putting its content to work.
When you extract text, you're essentially turning messy, unstructured website content into clean, structured data. This simple act unlocks a ton of possibilities for deep analysis, fresh content creation, and real strategic insight.
Getting a Strategic Edge with Web Data
The real-world uses are practically endless-and often quite impactful. Businesses are constantly pulling text to keep an eye on competitor pricing, check product stock, and sift through customer reviews. This kind of direct market intelligence is what allows them to pivot quickly and stay ahead of the curve.
For researchers and academics, it’s a goldmine. They rely on text extraction to build massive datasets for their work, whether it's analyzing public sentiment on social media or compiling decades of news articles. For anyone doing long-term analysis, learning how to build and search your own Twitter archive can be a game-changer.
Being able to systematically pull text from websites gives you a real-time, unfiltered view of your market, your competitors, and your customers. It’s the difference between guessing and knowing.
Powering a Data-Driven World
This growing dependence on web data isn't just a feeling; it's a huge economic force. The web scraping market, which is all about extracting text and other data, was valued at around USD 1.03 billion in 2025. It's on track to nearly double to USD 2.00 billion by 2030, which tells you just how central this practice has become across every industry. You can dive deeper into the web scraping market growth trends to see the numbers for yourself.
This boom is also what's fueling the next wave of AI. Large language models (LLMs)-the kind that power tools like WhisperChat.ai-are trained on unfathomable amounts of text scraped directly from the web. That massive data diet is what teaches them to understand language, answer our questions, and even write like a human. At its core, text extraction is a foundational pillar of modern AI.
Choosing Your Text Extraction Method
Not sure which method is right for you? This table breaks down the different approaches we'll cover, helping you match the tool to your specific task and technical comfort level.
| Method | Best For | Technical Skill | Speed |
|---|---|---|---|
| Manual Copy-Paste | Grabbing small, one-off snippets of text from a single page. | None | Slow for anything more than a paragraph. |
| Browser DevTools | Extracting specific, hard-to-copy text or clean HTML from one page. | Basic HTML/CSS | Moderate; faster than copy-paste. |
| Python Libraries | Bulk scraping thousands of pages or automating recurring data pulls. | Intermediate | Very Fast; scales for large projects. |
| WhisperChat.ai | Instantly extracting text from any URL with a simple prompt. | None | Instant; fastest for single pages. |
Each of these methods has its place. The best one for you really just depends on what you're trying to accomplish. Let's dive into how each one works.
Sometimes, the Simplest Tool is the Right One: The Copy and Paste Method
Let’s start with the most familiar method out there. Often, the quickest way to pull text from a website is the classic copy and paste you probably do a dozen times a day. It’s instinctual, requires zero setup, and is fantastic for those one-off grabs.
Imagine you’re trying to save a recipe from a food blog that’s cluttered with ads, a lengthy personal story, and a dozen links. You don't care about the navigation menu or the comments section; you just want the list of ingredients and the cooking steps. A quick highlight and copy is all it takes. For these immediate, small-scale tasks, setting up an automated tool would be like using a sledgehammer to crack a nut.
Dealing With the Messy Aftermath
The main headache with this method? You almost always end up with more than you bargained for. Your copied text brings along all its baggage-different fonts, weird text sizes, random colors, and a bunch of hyperlinks. The result is often a messy, unreadable document.
The trick is to paste without formatting. It’s a simple but powerful move that most applications support.
- Google Docs & Microsoft Word: Instead of the usual
Ctrl+V, use the magic shortcut:Ctrl+Shift+V(orCmd+Shift+Von a Mac). This strips out all the styling. - Plain Text Editors: Another great workaround is to use a basic editor as a middleman. Paste your text into Notepad (on Windows) or TextEdit (on Mac, just make sure it's in plain text mode) first. These tools don't support rich formatting, so they automatically clean the text for you. Then, you can copy the clean text and move it to its final destination.
Taking this extra second ensures you’re left with nothing but the words themselves, clean and uniform.
Take a look at this screenshot of a Wikipedia page. It's a perfect example of a page loaded with links, bold text, and other formatting.
If you just copied a chunk of this and pasted it directly, you'd get all the blue links and other styles. But if you paste without formatting, you get just the clean, raw text.
Knowing When to Upgrade Your Toolkit
As beautifully simple as it is, the copy-and-paste approach has its breaking point. It becomes incredibly tedious and error-prone when you need to extract more than a few paragraphs or repeat the process across multiple pages.
If you find yourself mindlessly copying and pasting the same kind of data from page after page-like product prices, customer reviews, or contact details-that's your cue. You've officially outgrown the manual method.
At this stage, the time you're losing to repetitive manual work far outweighs the simplicity of the approach. For any task that involves scale or repetition, you’ll be much better off exploring a more robust technique.
Using Browser Developer Tools for Precision
Sometimes, a simple copy-and-paste just doesn't work. When a webpage is cluttered with ads, pop-ups, and complex layouts, you need a more precise tool. The good news is, you already have one built right into your web browser.
Every major browser-Chrome, Firefox, Safari, Edge-includes a powerful suite of Developer Tools (often called "DevTools"). They let you look under the hood at a website's code, giving you surgical control to extract text from web pages, even from the trickiest spots.
Getting to them is easy. Just right-click anywhere on the page you want to extract from and select "Inspect" or "Inspect Element." A new panel will pop up showing the page's HTML structure. It can look a bit technical at first, but you only need to know the basics to get what you need.
Pinpointing Text with HTML Tags
On the web, all content is organized with HTML tags. Paragraphs usually live inside <p> tags, and headings are marked with <h1>, <h2>, etc. If you can find the right tag in the DevTools panel, you can isolate exactly the text you want to grab.
Let's imagine a real-world scenario. You're on a product page trying to copy all the customer reviews. The problem is, they're mixed in with product specifications, related items, and ads. A standard copy-paste would create a chaotic, jumbled mess.
This is where DevTools shines. Here’s how you can approach it:
- Inspect the first review. Right-click directly on the text of one review and select "Inspect."
- Identify the common container. The DevTools panel will instantly highlight the HTML code for that specific review. Look at the code around it-you’ll often notice that all the reviews are wrapped in a similar element, like a
<div>with a descriptive class name likeclass="review-item". - Copy the parent element. Once you find the main container holding all the reviews, right-click on it in the DevTools panel and choose "Copy" > "Copy element."
When you paste this into a text editor, you’ll get the clean HTML containing only the review content. It’s a much more reliable way to get structured text than trying to drag your mouse perfectly across the page. For a more technical look at how this works, you can read about how to fetch source text from a webpage.
Pro Tip: Don't get bogged down trying to understand every line of code. Your goal is simply to find the text you see on the page within the HTML. The "Inspect" feature does the heavy lifting for you by jumping you right to the relevant spot.
This manual inspection method is perfect for those one-off tasks where you need clean, detailed information without the clutter.
Take a look at the market research report page below. These pages are notorious for having dense data tables and text that are almost impossible to select cleanly with your mouse.

Here, you could use the "Inspect" tool to target the exact <table> element in the code. A quick right-click and copy would grab its entire contents, leaving behind all the navigation links and headers. For capturing structured data like this, it’s a game-changer.
When you need to pull text from hundreds or even thousands of web pages, manual methods just won't cut it. Copy-pasting or fiddling with browser DevTools for that kind of volume is a recipe for a very long, very tedious week. This is exactly where automation steps in to save the day.
If you're comfortable with a little bit of code, Python offers a remarkably powerful and flexible way to build your own text extraction machine. You don't need to be a seasoned software engineer; a few simple lines of code are often all it takes to automate a task that would otherwise consume countless hours.
The basic idea is straightforward: you write a short script that tells your computer to visit a webpage, grab all of its underlying content, and then neatly pluck out the specific text you're after.
For this job, two Python libraries stand out as the go-to toolkit: Requests and BeautifulSoup.
The Dynamic Duo: Requests and BeautifulSoup
Think of this process like getting a takeout order.
The Requests library is your delivery driver. You give it an address (a URL), and its one job is to go there and bring back whatever it finds-in this case, the raw HTML source code of the webpage. It’s fast, reliable, and handles all the messy details of making the connection.
Once the HTML arrives, BeautifulSoup is like your set of kitchen tools. It takes the jumbled, raw HTML that Requests fetched and organizes it into a clean, structured format. This lets you easily navigate the code and pinpoint the exact elements you need, whether it's article headlines, product descriptions, or user comments.
Requests fetches the whole page, and BeautifulSoup lets you slice and dice it to get the good stuff. It's a classic combination for a reason.
This kind of automated approach is no longer a niche skill; it's a fundamental part of how modern businesses operate. From e-commerce and marketing to finance and research, industries rely on web scraping to gather critical data. In fact, the market for these tools was projected to reach about $2.83 billion in 2025, a clear sign of how vital automated data extraction has become. You can dig deeper into the web scraping tools market to see just how big this trend is.
Putting It Into Practice with Code
So, what does this actually look like? Let's say you want to scrape all the product names from an online store's category page. After a quick look at the page's HTML, you notice all the product names are conveniently wrapped in <h2> tags.
Here’s how you could automate that with a simple Python script:
import requests from bs4 import BeautifulSoup
The URL of the page you want to scrape
url = 'https://example-store.com/laptops'
Use Requests to fetch the page content
response = requests.get(url)
Use BeautifulSoup to parse the HTML
soup = BeautifulSoup(response.content, 'html.parser')
Find all the h2 tags on the page
product_names = soup.find_all('h2')
Loop through the results and print the clean text for each one
for name in product_names: print(name.get_text())
Let's quickly break down what's happening here. The script first fetches the page with requests.get(url). Then, BeautifulSoup(...) parses that raw HTML. The magic happens with soup.find_all('h2'), which creates a list of every single <h2> element on the page. Finally, the script loops through that list and uses name.get_text() to extract only the clean, human-readable text, leaving the HTML tags behind.
Running this script would instantly give you a clean list of every product name on the page.
And this is just the beginning. You could easily tweak this code to find different tags, like <p> for paragraphs or <span> for prices. Better yet, you can build on this foundation to have your script automatically cycle through hundreds of different URLs, putting massive data collection power right at your fingertips.
Exploring No-Code Web Scraping Tools
What if you want all the power of automated data collection but the thought of coding makes your head spin? Good news. There's a whole world of no-code web scraping tools designed specifically for you. These platforms offer visual, point-and-click interfaces that let you extract text from web pages without ever writing a single line of code.
Essentially, these tools turn the often-tricky process of web scraping into a simple, mouse-driven task. You’re not digging through HTML or piecing together scripts. Instead, you just show the tool what you want by clicking on it, and it does the heavy lifting for you.

Building an Extractor Visually
Let's imagine you’re a market researcher, and you’ve been asked to compile a report on a competitor’s entire product line. You need to pull the name, price, and stock status for hundreds of items. Manually, that’s a mind-numbing task that could take days.
With a no-code tool, it’s a completely different story.
- First, you’d plug a product page URL into the tool.
- Once the page loads, you simply click on the product's name. Then its price. Then its stock status.
- The tool is smart enough to recognize a pattern. You then tell it to repeat that process for every similar product page on the website.
From there, the tool gets to work, automatically hopping from page to page, grabbing the exact pieces of information you pointed out. It neatly organizes everything into a structured spreadsheet, saving you a massive amount of time and effort. It's a game-changer for non-technical users.
These tools open up large-scale data automation to everyone-marketers, entrepreneurs, analysts, and anyone who needs data but doesn't have a development background.
Real-World Applications and Use Cases
This point-and-click approach is incredibly effective in e-commerce, where businesses constantly scrape competitor sites for pricing intelligence, product specs, and customer reviews. Real estate firms do something similar, pulling property listings from multiple sources to keep their own databases fresh.
Even on a smaller scale, this method is handy. For instance, people interested in tracking specific deals might find that setting up Craigslist alerts uses these same extraction principles to monitor new posts automatically.
Modern AI platforms are making this even simpler. Some tools just need a list of websites, and the AI handles the rest. Our own guide on how to fetch URLs for AI processing explains how you can feed web content directly into systems like WhisperChat.ai. It’s the perfect no-code solution for anyone who needs web data fast, without getting bogged down in the technical details.
So, you've got a few powerful techniques under your belt. How do you decide which one to use? The right way to extract text from web pages really boils down to what you're trying to accomplish. There isn't a single "best" method, just the one that makes the most sense for the job at hand.
Think of it like choosing the right tool for a home repair project. You wouldn't use a sledgehammer to hang a picture frame, and you wouldn't use a tiny screwdriver to break up concrete. It's all about matching the tool to the task.
Picking Your Method Based on the Job
Let's walk through a few real-world situations to see how this plays out.
Need to grab just one article? If all you want is the text from a single blog post or news story to read later, don't overcomplicate it. A quick manual copy and paste is your best friend. It’s instant and doesn't require any special tools.
Extracting a few specific things? Say you need to pull 50 product descriptions from a messy e-commerce site or a dozen reviews from a single page. This is where your browser's Developer Tools shine. They offer surgical precision, letting you target exactly what you need without setting up a complex script.
The most important question you can ask is, "How often am I going to do this?" If your answer is "just this once," or even "a handful of times," stick with the manual approaches. But if it's "every day," "every week," or "thousands of times," it's time to think about automation.
When Automation is the Only Answer
Automation stops being a "nice to have" and becomes a necessity when you're dealing with serious scale or repetition.
For example, imagine you need to track the prices of 1,000 competitor products every single day. Trying to do that by hand is a non-starter; you'd never keep up. This is the perfect job for a Python script or a no-code tool. These methods are designed to perform the same task over and over again, at a scale that's impossible for a human.
AI-powered platforms can take this a step further. A tool like WhisperChat.ai, for instance, can pull web content directly into its system for analysis or other tasks. If you're curious about how that works, our documentation explains how to fetch source texts for AI processing.
Ultimately, choosing the right method is about finding the sweet spot between your own technical comfort and the scale of your project. My advice? Start with the simplest tool that gets the job done and only move to more advanced methods as your needs evolve.
Getting Your Questions Answered About Web Text Extraction
As you move from simple copy-pasting to more serious web text extraction, you'll naturally run into some common questions. Thinking through these points upfront can save you a ton of headaches down the road, especially before you commit to a big project.
Is This Even Legal?
Let's get the big one out of the way first: Is it legal to scrape a website? Generally speaking, grabbing publicly available information is fair game. However, you absolutely have to play by the website's rules.
Before you do anything, check the site's robots.txt file. You can usually find it by typing domain.com/robots.txt into your browser. This simple text file tells bots which parts of the site they're allowed to access and which are off-limits. You should also take a look at the Terms of Service to see what they say about automated access or scraping. Staying on the right side of these rules is crucial.
What About Websites That Change on the Fly?
One of the biggest technical challenges you'll face is dynamic content. Many modern sites use JavaScript to load key information-think product prices, user reviews, or search results-after the main page has already loaded. If you just send a basic request for the page's HTML, that dynamic text simply won't be there.
This infographic breaks down how to choose the right tool for the job.
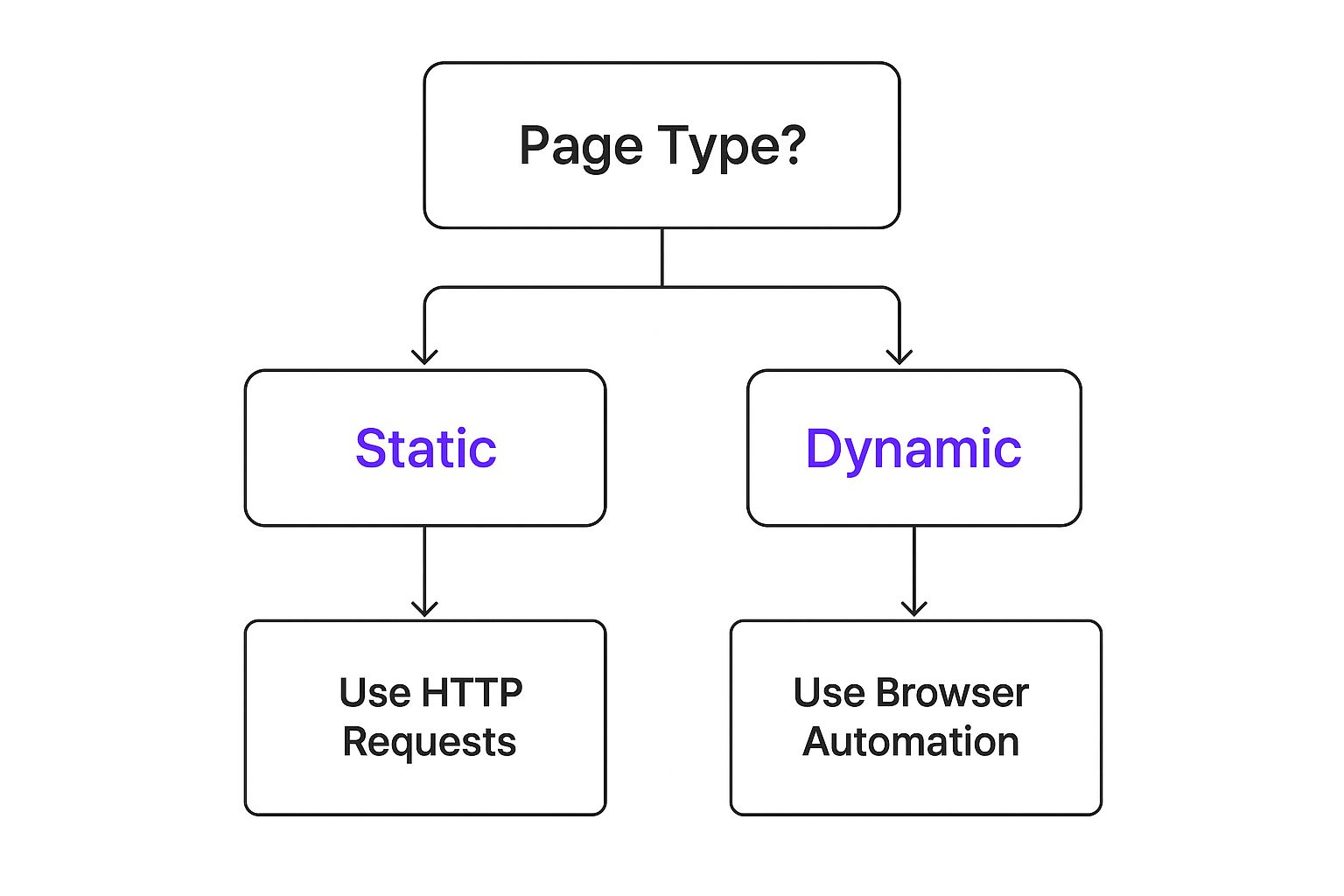
The takeaway here is that static and dynamic sites require completely different approaches. For those dynamic pages, you'll need something that can actually run the JavaScript, just like a real browser. This means turning to tools like Selenium or Playwright, or using a more sophisticated no-code tool built for this exact purpose.
Another classic problem? Website layouts change. You might build a scraper that perfectly targets a price inside a
<span>tag with a specific class, only to have it break the moment a developer decides to rename that class. Building robust scrapers means creating flexible selectors that don't depend on flimsy details. This adaptability is the secret to successful, long-term text extraction.
Keeping these legal and technical realities in mind will help you build much more resilient and effective workflows from the start.
Ready to skip the technical hurdles and extract text from any website instantly? WhisperChat.ai trains an AI assistant on your web content, PDFs, or other documents. The result is a custom chatbot ready to answer your customer's questions 24/7. You can get started for free at WhisperChat.ai.